

Was ist eine Robots Datei?
Bei der Robots Datei (robots.txt) handelt es sich um eine Textdatei, mit welcher man Crawler beim Besuch einer Website steuern kann. So kann man beispielsweise festlegen, welche Bereiche/Seiten einer Domain von einem Crawler durchsucht werden dürfen und welche nicht.
Die robots.txt ist dabei das erste Dokument, das ein Crawler aufruft, sobald er eine Website besucht. Erst danach werden unter Beachtung der Anweisungen aus der Robots Datei die restlichen Webseiteninhalte gecrawlt und ggf. indexiert.
Außerdem kann man in der Robots Datei einen Verweis auf die XML-Sitemap angeben, damit Crawler die URL-Struktur einer Website leichter verstehen und damit besser durchforsten können.
Wie ist die Robots Datei aufgebaut?
Der einfachste Aufbau einer robots.txt sieht folgendermaßen aus:
User-agent: *
Disallow:
User-agent
Hinter „User-agent“ geben wir den Crawler ein, auf welchen sich die folgenden Anweisungen beziehen sollen. Mit dem Sternchen (*) sprechen wir alle Bots an.
Wollen wir nur einen bestimmten Bot ansprechen, müssen wir statt dem Sternchen den entsprechenden Namen eintragen. Je nach Suchmaschine unterscheiden sich die Namen der Crawler wie folgt:
- • Googlebot (Google)
- • Googlebot-Image (Google Bildersuche)
- • Adsbot-Google (Google AdWords)
- • Googlebot-Mobile (Google Mobile)
- • Slurp (Yahoo)
- • Bingbot (Bing)
Wenn wir unsere Anweisungen also speziell auf den Googlebot beziehen möchten, müssen wir folgendes in die Robots Datei eingeben:
User-agent: Googlebot
Disallow:
Disallow
Über Disallow können wir dem Crawler verbieten, bestimmte Bereiche unserer Website zu betreten. Tragen wir hier wie in unserem Beispiel gar nichts ein, darf er alle Bereiche der Seite betreten.
Wollen wir ihm hingegen das Betreten der gesamten Seite untersagen, muss folgende Anweisung hinter den Doppelpunkt:
Disallow: /
Wollen wir nur das Crawlen einzelner Verzeichnisse oder Dateien verbieten, lautet der Befehl z.B.:
Disallow: /wp-admin/
Disallow: /Userprofile/profil.html
Disallow /meineprivatenFotos/
XML Sitemap
Wie eingangs erwähnt, können wir auch einen Verweis auf die XML Sitemap angeben. Dies erfolgt über diese Anweisung:
Sitemap: http://www.ihredomain.de/sitemap.xml
Spezialfall „Mobile-Site“
Mit der robots.txt kann man auch eine Mobile Website von einer Desktop Website „trennen“. Und zwar, indem man die mobilen Bots auf der Desktop-Variante sperrt und die „normalen“ Bots auf der Mobile Site. Die Anweisung hierfür würde wie folgt aussehen:
Desktop-Site:
User-Agent: Googlebot-Mobile
Disallow: /
Mobile Site:
User-Agent: Googlebot
Disallow: /
Wie erstelle ich die Robots Datei?
Die Robots Datei kann mit einem einfachen Editor erstellt werden, z.B. mit dem kostenlosen Notepad++ (Textverarbeitungsprogramme wie Microsoft Word usw. eignen sich dafür nicht!).
Hierfür muss einfach eine neue Datei mit den gewünschten Anweisungen erstellt und unter dem Namen „robots.txt“ abgespeichert werden.
Anschließend muss die Datei über ein FTP-Programm wie FileZilla in das Root-Verzeichnis Ihrer Website hochgeladen werden.
Wie kann ich die Robots Datei aufrufen?
Da sich die Robots Datei immer im Root-Verzeichnis einer Website befindet, kann diese aufgerufen werden, indem der Dateiname direkt an die Domain gehängt wird, also z.B.
https://www.ihredomain.de/robots.txt/
Erhalten Sie eine 404 Fehlerseite, dann existiert noch keine Robots Datei oder sie wurde in das falsche Verzeichnis hochgeladen.
Warum sollte man Crawlern den Besuch bestimmter Seiten untersagen?
Es gibt verschiedene Gründe, warum es sinnvoll sein kann, das Crawlen bestimmter Seiten zu untersagen:
- Nicht alle Crawler, die Ihre Seite besuchen, haben gute Absichten. Es gibt viele Robots, deren einziger Zweck im Scannen Ihrer Webseite besteht und dem damit verbundenen Extrahieren Ihrer E-Mail-Adresse zum Zwecke von Spam.
- Möglicherweise haben Sie Ihre Webseite noch nicht fertig gestellt oder sie beinhaltet bestimmte, zu schützende Teile.
- Sie besitzen einen Mitgliedsbereich, der nicht im Google Cache auftauchen soll.
- Es gibt Dinge, die Sie vielleicht privat halten möchten. Dies kann bestimmtes Bildmaterial sein oder urheberrechtlich geschützte Inhalte.
Doch vorsicht: das Crawlen einer Website zu untersagen, bedeutet nicht zwangsläufig, dass diese auch nicht im Suchmaschinenindex gelistet wird. Ist eine Seite bereits im Index aufgenommen, kann sie durch die Disallow-Anweisung nicht entfernt werden. Lesen Sie hierzu den Beitrag über “noindex“.
Die robots.txt zum Schluss noch mit der Google Search Console testen
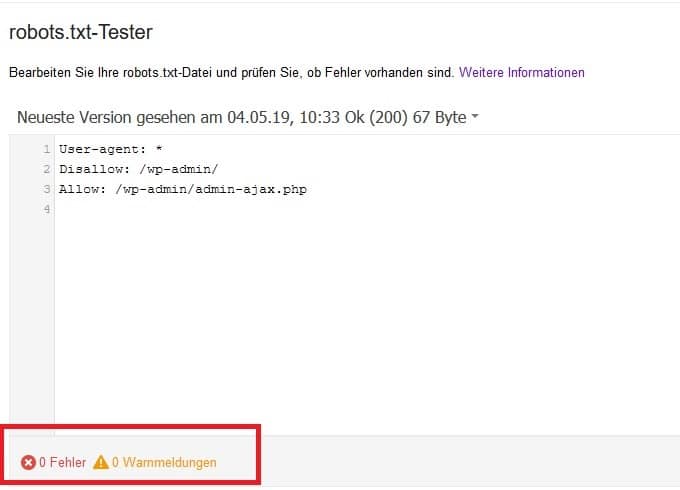
Google stellt in der Google Search Console einen kostenlosen robots.txt Tester zur Verfügung. Diesen können Sie benutzen um zu überprüfen, ob alle Anweisungen in der Robots Datei richtig erfolgt sind.
Ist die Robots Datei korrekt hinterlegt, wird sie hier angezeigt. Es sollten 0 Fehlermeldungen und 0 Warnungen ausgegeben werden.
Darüber hinaus können Sie darunter eine URL eingeben, bei welcher Sie überprüfen möchten, ob sie durch die robots.txt blockiert wurde.


