
Was bedeutet Duplicate Content?
Duplicate Content (= doppelter Inhalt) ist ein Begriff, der hauptsächlich im Zusammenhang mit der Suchmaschinenoptimierung verwendet wird.
Von Duplicate Content spricht man, wenn identische oder sehr ähnliche Texte über mehrere URLs erreichbar sind.
Wenn Sie also diesen Blogartikel 1:1 kopieren und auf Ihrer eigenen Webseite wieder 1:1 veröffentlichen, wäre dies solch ein doppelter Inhalt (und darüber hinaus natürlich auch eine sehr dreiste Urheberrechtsverletzung ? ).
Wie entsteht Duplicate Content und wie kann ich ihn vermeiden?
Duplicate Content muss nicht zwangsläufig immer dadurch entstehen, dass ein anderer Ihren hart erarbeiteten Text stiehlt und sich mit Ihren Federn schmückt.
Meistens entsteht Duplicate Content eher unbeabsichtigt, sodass Seitenbetreiber ihn oftmals lange Zeit gar nicht bemerken. Die Ursachen hierfür sind vielfältig und eher technischer Natur:
Ursache: www vs. non-www
Sobald Ihre Webseite sowohl unter www.ihrewebseite.de, als auch unter ihrewebseite.de zu erreichen ist und dort die gleichen Inhalte ausgeliefert werden, produzieren Sie doppelte Inhalte.

Lösung:
Mit einer kleinen Anpassung der .htaccess können Sie dieses Problem beheben.
Die .htaccess finden Sie über ein FTP-Programm wie Filezilla im Root-Verzeichnis Ihres Webservers. Dort können Sie beispielsweise mit folgendem Code eine non-www Domain auf eine www Domain umleiten:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^ihrewebseite.de
RewriteRule ^(.*)$ https://ihrewebseite.de$1 [R=301,L]
Das Ganze funktioniert natürlich auch anders herum:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.ihrewebseite.de
RewriteRule ^(.*) http://ihrewebseite.de$1 [R=301,L]
Ursache: HTTP vs HTTPS
Sobald Ihre Webseite im Zuge der Einbindung eines SSL Zertifikats sowohl in der HTTP-Version, als auch in der HTTPS-Version aufrufbar ist, erzeugen Sie ebenfalls Duplicate Content.
Lösung:
Tragen Sie dafür Sorge, dass Ihre Webseite nur noch unter der HTTPS-Version zu erreichen ist. Alle HTTP-Anfragen müssen mittels 301-Redirect auf die HTTPS-Version umgeleitet werden.
Nachfolgend haben wir für Sie bereits den kompletten Code für Ihre .htaccess-Datei bereit gestellt. Bitte fügen Sie diesen wie nachstehend ein.
RewriteEngine On
RewriteCond %{HTTPS} off
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
Ursache: URL einmal groß- und einmal kleingeschrieben
Google unterscheidet zwischen Groß- und Kleinschreibung,
Lösung:
Verwenden Sie bei Ihren URLs ausschließlich die Kleinschreibung, um Duplicate Content von vornherein zu vermeiden.
Ursache: Paginierung
Paginationsseiten werden häufig in Onlineshops eingesetzt, um lange Produktseiten zu kürzen:
Lösung:
Um den Zusammenhang zwischen einer Hauptkategorieseite und den Paginationsseiten ersichtlich zu machen, sollte man die neuen Elemente rel=“next“ und rel=“prev“ verwenden. Mit Hilfe dieser Elemente kann man leicht die Hauptkategorieseite und die Paginationsseiten definieren und sicherstellen, dass der Fokus für Google auf der Hauptkategorieseite liegt. Folgendes Beispiel mit drei Seiten macht die Verwendung deutlich:
HTML
Auf der ersten Seite wird im Header folgendes implementiert:
<link rel=”next” href=”http://www.example.com/article?story=abc&page=2″ />
Auf der zweiten Seite erscheint:
<link rel=”prev” href=”http://www.example.com/article?story=abc&page=1″ />
<link rel=”next” href=”http://www.example.com/article?story=abc&page=3″ />
Und auf der dritten Seite:
<link rel=”prev” href=”http://www.example.com/article?story=abc&page=2″ />
Das Beispiel macht deutlich, welche Regeln man beachten muss. Die erste Seite darf nur das Element rel=“next“ beinhalten, die zweite Seite (also alle Seiten, die zwischen der ersten und der letzten Seite liegen) beide Elemente rel=“next“ und rel=“prev“ und die dritte Seite nur das Element rel=“prev“. So erkennt Google eine klare Strukturierung. Eine Verwendung von Canonical-Tags und den Elementen rel=“next“ und rel=“prev“ in Kombination ist ebenfalls möglich. Dies macht Sinn, wenn eine Paginationsseite zusätzlich über eine URL mit einer Session-ID erreichbar ist, zum Beispiel http://www.example.com/article?story=abc&page=2&sessionid=123. Um die Canonical-URL anzeigen zu können, müsste diese Paginationsseite im Header folgende Informationen beinhalten:
HTML
<link rel=”canonical” href=”http://www.example.com/article?story=abc&page=2”/><link rel=”prev” href=”http://www.example.com/article?story=abc&page=1&sessionid=123″ /><link rel=”next” href=”http://www.example.com/article?story=abc&page=3&sessionid=123″ />
Ursache: Identische oder sehr ähnliche Produktbeschreibungen

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Lösung:
Tja – ran an den Stift. Denn hier hilft nur die Erstellung eigener, einzigartiger Produkttexte.
Ursache: URL Parameter und Session-IDs
Vor allem in Onlineshops sind Session-IDs eine praktische Sache. Legt ein Nutzer Produkte in den Warenkorb und verlässt die Seite vorerst wieder ohne etwas zu kaufen, kann es ärgerlich sein, wenn beim erneuten Aufruf der Seite der Warenkorb plötzlich leer ist. Mithilfe von Session-IDs bleiben die Produkte auch bei seiner Rückkehr noch im Warenkorb.
Das Problem: Für jeden Nutzer wird über dieselbe URL eine neue Session-ID generiert, was letztendlich zu doppeltem Inhalt führt.
Auch Trackingtools verwenden Session-IDs, um das Nutzerverhalten zu analysieren. Hier wird ebenfalls für jeden Nutzer eine neue ID und damit Duplicate Content erzeugt.
Ursache: Mobile Version einer Webseite
Die mobile Version einer Webseite ist nicht zu verwechseln mit dem responsive Webdesign einer Seite. Bei einem responsive Design wird nur ein Webseiten Layout erstellt, welches sich flexibel an die verwendete Bildschirmgröße anpasst.
Es gibt jedoch auch die Möglichkeit, ein komplett eigenständiges Layout für die mobile Version einer Webseite zu erstellen, welche dann beispielsweise über eine Subdomain aufrufbar ist.
Da die mobile Version in der Regel dieselben Inhalte aufweist, wie die Desktop-Version, sich aber durch die Subdomain auf einer anderen URL befindet, führt dies zu Duplicate Content.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Lösung:
Falls Sie eine oder mehrere Seiten mit sehr ähnlichen oder identischen Inhalten haben, dann können Sie mithilfe des Canonical Tags Google mitteilen, welche URL er bevorzugt behandeln soll.
Platzieren Sie den Canonical Tag auf der bevorzugten Version im <head> Bereich der entsprechenden Seite wie folgt:
<head>
<link rel=“canonical“ href=”https://ihredomain.de/beispiel-seite/“ />
</head>
Ursache: PDF- und Print-Version einer Webseite
Lösung:
Auch hier bietet sich die Platzierung des Canonical-Tags im Head-Bereich der Hauptseite an:
<head>
<link rel=“canonical“ href=”https://ihredomain.de/hauptseite/“ />
</head>
Ursache: Domainumzug
Lösung:
Mithilfe der dauerhaften Weiterleitung mit 301 Redirect können Sie alte (nicht mehr existierende) Dateien bzw. Seiten auf eine neue umleiten bzw. auch gleich eine ganze Domain. Der Vorteil bei einem 301 Redirect liegt darin, dass der bisherige PageRank der alten Seite mit auf das neue Ziel übertragen wird! Wenn Sie nach dieser Methode vorgehen müssen Sie also bei einem Domainumzug bzw. einem Website-Relaunch nicht befürchten, Ihren alten PageRank (bzw. Ihre alte Google-Platzierung) zu verlieren.
Hierfür müssen Sie ebenfalls die .htaccess im Root-Verzeichnis Ihrer ALTEN Domain um folgende Zeile ergänzen:
Wenn Sie eine einzelne Datei bzw. Seite bzw. Unterseite umleiten möchten:
RedirectPermanent /seite-alt.html https://ihredomain.de/seite-neu.html
Oder wenn Sie eine ganze Domain umleiten möchten:
RedirectPermanent / https://domain-neu.de
Ursache: Unterschiedliche Sprachversionen einer Webseite
Grundsätzlich werden Übersetzungen einer Seite von Google natürlich nicht als Duplikate gewertet.
Nehmen wir jedoch an, Sie bieten Ihre Webseite in mehreren Ländern mit derselben Sprache an, zum Beispiel für die D-A-CH Region. Für jedes der drei Länder haben Sie nun ein eigenes Verzeichnis angelegt:
www.ihredomain.de/de/ für die deutschen Besucher
www.ihredomain.de/at/ für Nutzer aus Österreich und
www.ihredomain.de/ch/ für Besucher aus der Schweiz
Da sich nun in allen drei Verzeichnissen identischer Text in derselben Sprache befindet, wird dies als Duplicate Content gewertet.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Lösung:
Mit dem hreflang-Tag können Webseiten-Inhalte einer bestimmten Sprache bzw. Region zugeordnet werden. Der hreflang-Tag wird dafür im Kopfbereich (head) der jeweiligen Version hinzugefügt.
<link rel=“alternate” hreflang=“de-DE” href=“https://www.beispiel.com/de/”/>
<link rel=“alternate” hreflang=“de-AT” href=“https://www.beispiel.com/at/”/>
<link rel=“alternate” hreflang=“de-CH” href=“https://www.beispiel.com/ch/”/>
Ursache: Duplicate Content durch das Erstellen einer Entwicklungsumgebung
Größere oder kritische Änderungen an einer Webseite führen die meisten Entwickler ungern direkt an der Live-Version der Seite durch. Stattdessen wird eine Kopie der Seite auf einem anderen Server hochgeladen, damit, falls etwas schief läuft, die Live Seite keinen Schaden nimmt. Bei einer unsauberen Handhabung kann es schnell passieren, dass die Testseite in den Google Index rutscht und so dem Ranking der eigentlichen Seite schadet.
Lösung:
Damit es bei Einsatz einer Entwicklungsumgebung nicht zu Duplicate Content kommt, sollten Sie die Testseite zunächst mit einem Passwortschutz versehen. Außerdem sollten Sie die Testseite von Anfang an vollständig auf „noindex“ stellen und Suchmaschinencrawlern so die Indexierung der Seite untersagen. Alternativ können Sie auch eine Robots Datei nutzen, um Suchmaschinen das Betreten Ihrer Seite zu verweigern.
Vergessen Sie nicht, Suchmaschinen den Zugriff und die Indexierung bei Live-Schaltung der Seite wieder zu erlauben!
Ursache: Content Diebstahl
Klaut ein anderer Seitenbetreiber Ihre Inhalte, kann das Ranking Ihrer Webseite durch den dadurch entstehenden Duplicate Content Schaden nehmen.
Lösung:
Zunächst sollten Sie Kontakt zum Betreiber der Seite aufnehmen und ihn um die vollständige Löschung des kopierten Inhalts bitten. Die Kontaktdaten lassen sich normalerweise im Impressum der Seite finden. Alternativ kann über Denic oder Whois der Inhaber der Domain ermittelt werden.
Da das Kopieren von Inhalten einen Urheberrechtsverstoß darstellt, reicht eine Kontaktaufnahme in der Regel schon aus, damit der Betreiber der Bitte um Entfernung nachkommt. Sollte jedoch niemand auf Ihre Kontaktaufnahme reagieren, können Sie über Whois ermitteln, über wen die Seite gehostet wird. Die meisten Hoster bieten auf ihrer Webseite bereits ein sogenanntes DMCA Formular (DMCA = Digital Millenium Copyright Act) an, über welches Urheberrechtsverstöße auf den von ihnen gehosteten Seiten übermittelt werden können. Liegt tatsächlich eine Urheberrechtsverletzung vor, wird sich der Hoster um die Löschung der kopierten Inhalte kümmern. Sollte auch das nicht zum Erfolg führen, können Sie sich aber auch direkt an Google wenden und um die De-Indexierung des kopierten Inhalts bitten. Auch hier stellt Google ein entsprechendes DMCA Formular zur Verfügung.
Ob Sie zudem rechtlich gegen den Content-Dieb vorgehen möchten, bleibt Ihnen selbst überlassen. Ist der kopierte Text grundsätzlich schutzfähig, können Sie den Content-Dieb auf Urheberrechtsverletzung verklagen. Handelt es sich um einen direkten Mitbewerber, können Sie auch vom UWG (Gesetzt gegen unlauteren Wettbewerb) Gebrauch machen.
SEO: Wie geht Google mit Duplicate Content um?
Eines ist klar: Google bevorzugt hochwertigen und vor allem einzigartigen Content (= Unique Content).
Landet der Google Bot auf einer Webseite, welche sich noch nicht im Suchmaschinenindex befindet, vergleicht er deren Inhalte zunächst mit allen Inhalten bereits indexierter Webseiten. So versucht der Suchmaschinenriese die Relevanz der Webseite für gewisse Themen im Vergleich zu anderen einzuschätzen. Entsprechend der Relevanz wird die Seite dann in die Reihenfolge – dem Google Ranking – gebracht.
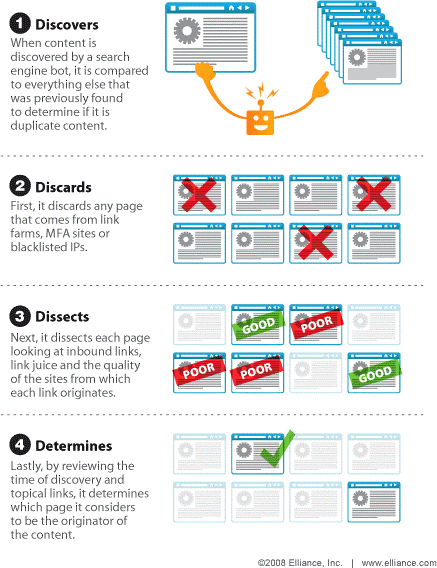
Stößt der Google Bot dabei auf zwei Webseiten mit identischen Texten, steht er vor einem Problem. Er kann nicht beide Seiten in den Google Index aufnehmen, weil es für den Nutzer keinen Mehrwert hätte, wenn er bei seiner Suche lauter identische Seiten als Ergebnis bekommt. Immerhin setzt der Suchmaschinenriese alles daran, Nutzern das beste Suchergebnis zu liefern.
Somit muss Google nun entscheiden, welche der beiden Seiten relevanter für das Suchergebnis ist. Also versucht er mittels verschiedener Kriterien zu ermitteln, welche der beiden Seiten die Originalversion darstellt. Mögliche Kriterien hierfür können sein:
- ◾ Das Erstelldatum der Originalversion im Vergleich zur Kopie
- ◾ Die Anzahl an Backlinks der Originalseite verglichen mit denen der Kopie
- ◾ Die Anzahl der Social Signals der Originalversion gegenüber der Kopie
Natürlich führt dieses Ratespiel häufig dazu, dass aus Sicht des Publishers genau die falsche Seite im Index landet, während die Seite, welche eigentlich ranken sollte, im Google Nirwana verschwindet.
Kann Google sich nicht für eine Originalversion entscheiden, wird die Relevanz auf beide Seiten aufgeteilt und somit wertvolles Rankingpotenzial verschwendet. Außerdem kann es passieren, dass beide URLs bei Google nun abwechselnd auftauchen. Das angestrebte beständige Ranking ist dadurch nicht möglich.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Sonderbehandlung von Zitaten
Zitate oder zitierte Textpassagen werden nicht als Duplicate Content gewertet. Bei der Zitierung von Inhalten sollte jedoch auf die korrekte Auszeichnung im Quelltext geachtet werden:
<blockquote>Hier steht der zitierte Text – <cite>Hier steht der Name des zitierten Autors oder der Quelle</cite></blockquote>
Arten von Duplicate Content
Man unterscheidet grundsätzlich zwei verschiedene Arten von Duplicate Content:
Interner Duplicate Content
Von internem Duplicate Content spricht man, wenn sich identische Inhalte innerhalb Ihrer eigenen Domain befinden. Wenn ein und derselbe Text also zum Beispiel sowohl über www.ihredomain.de/text_1 , als auch über www.ihredomain.de/text_2 aufrufbar ist.
Interner Duplicate Content hat meistens technische Ursachen.
Externer Duplicate Content
Von externen Kopien spricht man, wenn sich dieselben oder nahezu deckungsgleiche Inhalte auf zwei oder mehr unterschiedlichen Webseiten bzw. Domains befinden.
Ein klassisches Beispiel von externem Duplicate Content sind Onlineshops, die Produkttexte des Herstellers 1:1 kopieren und in ihrem Shop wiederverwenden. Doch auch durch die Verbreitung von identischen Pressemitteilungen oder Content Diebstahl entstehen externe Duplikate.
Near Duplicate Content

Wie kann ich überprüfen, ob meine Webseite von Duplicate Content betroffen ist?
Um Ihre Webseite auf internen Duplicate Content zu überprüfen, empfehlen wir das kostenlose Online-Tool Siteliner. Tragen Sie einfach Ihre Domain in das dafür vorgesehene Feld ein und klicken Sie anschließend auf “Go”:

Je nach Umfang der Seite kann es nun einige Minuten dauern, bis der Scan beendet ist. Anschließend erhalten Sie die Auswertung zum prozentualen Anteil des Duplicate Contents auf Ihrer Webseite für jede einzelne Unterseite. Identische Inhalte werden vom Tool rot markiert, sodass Sie direkt sehen können, wo auf Ihrer Webseite sich Duplicate Content befindet. Wobei bei einer niedrigen Prozentzahl noch nicht unbedingt ein Duplicate Content Problem vorliegen muss. Manche Inhalte wiederholen sich nun einmal auf einer Webseite, wie beispielsweise die Hauptnavigation, wichtige Boilerplates oder Angaben im Footer. Handeln sollten Sie aber bei Seiten, die 30% oder mehr doppelte Inhalte aufweisen.
Um Ihre Webseite auf externen Duplicate Content zu überprüfen, empfehlen wir das ebenfalls kostenlose Online Tool Copyscape. Auch hier tragen Sie zunächst Ihre URL in das Feld ein:

Das Tool ermittelt nun, ob Inhalte Ihrer Webseite auf anderen externen URLs zu finden sind. Copyscape eignet sich daher beispielsweise sehr gut, um Content Diebstahl zu überprüfen.

